
Java 笔记 2021.03.30.md
java
深拷贝
通过上面的例子可以看到,浅拷贝会带来数据安全方面的隐患,例如我们只是想修改了 studentB 的 subject,但是 studentA 的 subject 也被修改了,因为它们都是指向的同一个地址。所以,此种情况下,我们需要用到深拷贝。
深拷贝,在拷贝引用类型成员变量时,为引用类型的数据成员另辟了一个独立的内存空间,实现真正内容上的拷贝。
(1) 对于基本数据类型的成员对象,因为基础数据类型是值传递的,所以是直接将属性值赋值给新的对象。基础类型的拷贝,其中一个对象修改该值,不会影响另外一个(和浅拷贝一样)。
(2) 对于引用类型,比如数组或者类对象,深拷贝会新建一个对象空间,然后拷贝里面的内容,所以它们指向了不同的内存空间。改变其中一个,不会对另外一个也产生影响。
(3) 对于有多层对象的,每个对象都需要实现 Cloneable 并重写 clone() 方法,进而实现了对象的串行层层拷贝。
(4) 深拷贝相比于浅拷贝速度较慢并且花销较大。
public class Student implements Cloneable {
//引用类型
private Subject subject;
//基础数据类型
private String name;
private int age;
public Subject getSubject() {
return subject;
}
public void setSubject(Subject subject) {
this.subject = subject;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
/**
* 重写clone()方法
* @return
*/
@Override
public Object clone() {
//深拷贝
try {
// 直接调用父类的clone()方法
Student student = (Student) super.clone();
student.subject = (Subject) subject.clone();
return student;
} catch (CloneNotSupportedException e) {
return null;
}
}
@Override
public String toString() {
return "[Student: " + this.hashCode() + ",subject:" + subject + ",name:" + name + ",age:" + age + "]";
}
}
Java集合
常用集合的分类:
Collection 接口的接口 对象的集合(单列集合)
├——-List 接口:元素按进入先后有序保存,可重复
│—————-├ LinkedList 接口实现类, 链表, 插入删除, 没有同步, 线程不安全
│—————-├ ArrayList 接口实现类, 数组, 随机访问, 没有同步, 线程不安全
│—————-└ Vector 接口实现类 数组, 同步, 线程安全
│ ———————-└ Stack 是Vector类的实现类
└——-Set 接口: 仅接收一次,不可重复,并做内部排序
├—————-└HashSet 使用hash表(数组)存储元素
│————————└ LinkedHashSet 链表维护元素的插入次序
└ —————-TreeSet 底层实现为二叉树,元素排好序
Map 接口 键值对的集合 (双列集合)
├———Hashtable 接口实现类, 同步, 线程安全
├———HashMap 接口实现类 ,没有同步, 线程不安全-
│—————–├ LinkedHashMap 双向链表和哈希表实现
│—————–└ WeakHashMap
├ ——–TreeMap 红黑树对所有的key进行排序
└———IdentifyHashMap
————————————————
List:
(1)ArrayList:底层数据结构是数组,查询快,增删慢,线程不安全,效率高,可以存储重复元素
ArrayList 多线程调用add() 方法时可能会发生覆盖 初始容量10 扩容1.5倍+1
(2)LinkedList 底层数据结构是链表,查询慢,增删快,线程不安全,效率高,可以存储重复元素
(3)Vector:底层数据结构是数组,查询快,增删慢,线程安全,效率低,可以存储重复元素
Hashmap 负载因子0.75 初始容量16 扩容2倍
JVM
新生代收集器:Serial、ParNew、Parallel Scavenge。
老年代收集器:Serial Old、CMS、Parallel Old。
堆内存垃圾收集器:G1。
(1)Serial 是一款用于新生代的单线程收集器,采用复制算法进行垃圾收集。Serial 进行垃圾收集时,不仅只用一条线程执行垃圾收集工作,它在收集的同时,所有的用户线程必须暂停(Stop The World)。
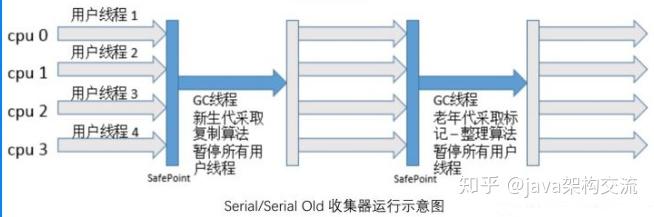
(2)ParNew 就是一个 Serial 的多线程版本,其它与Serial并无区别。ParNew 在单核 CPU 环境并不会比 Serial 收集器达到更好的效果,它默认开启的收集线程数和 CPU 数量一致,可以通过 -XX:ParallelGCThreads 来设置垃圾收集的线程数。
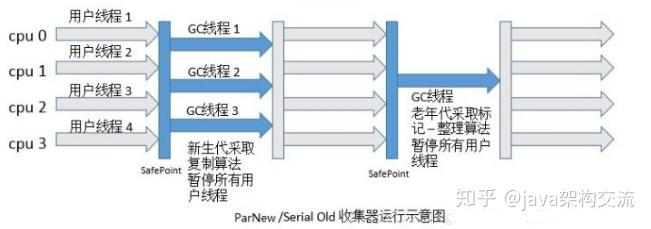
(3)Parallel Scavenge 也是一款用于新生代的多线程收集器,与 ParNew 的不同之处是,ParNew 的目标是尽可能缩短垃圾收集时用户线程的停顿时间,Parallel Scavenge 的目标是达到一个可控制的吞吐量。
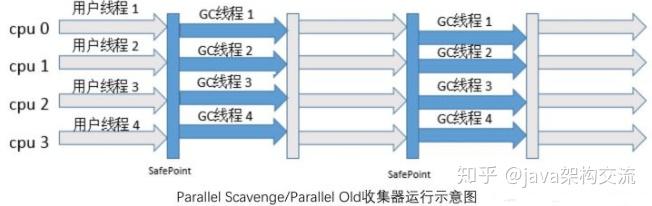
(4)Serial Old 收集器是 Serial 的老年代版本,同样是一个单线程收集器,采用标记-整理算法。
(5) CMS 收集器是一种以最短回收停顿时间为目标的收集器,以 “ 最短用户线程停顿时间 ” 著称。整个垃圾收集过程分为 4 个步骤:
① 初始标记:标记一下 GC Roots 能直接关联到的对象,速度较快。
② 并发标记:进行 GC Roots Tracing,标记出全部的垃圾对象,耗时较长。
③ 重新标记:修正并发标记阶段引用户程序继续运行而导致变化的对象的标记记录,耗时较短。
④ 并发清除:用标记-清除算法清除垃圾对象,耗时较长。
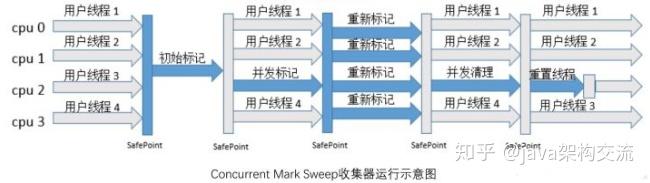
(6)Parallel Old 收集器是 Parallel Scavenge 的老年代版本,是一个多线程收集器,采用标记-整理算法。可以与 Parallel Scavenge 收集器搭配,可以充分利用多核 CPU 的计算能力。
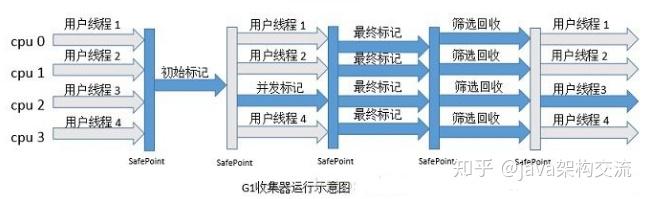
(7)G1 收集器是 jdk1.7 才正式引用的商用收集器,现在已经成为 jdk9 默认的收集器。前面几款收集器收集的范围都是新生代或者老年代,G1 进行垃圾收集的范围是整个堆内存,它采用 “ 化整为零 ” 的思路,把整个堆内存划分为多个大小相等的独立区域(Region),
G1 收集器可以 “ 建立可预测的停顿时间模型 ”,它维护了一个列表用于记录每个 Region 回收的价值大小(回收后获得的空间大小以及回收所需时间的经验值),这样可以保证 G1 收集器在有限的时间内可以获得最大的回收效率。
如下图所示,G1 收集器收集器收集过程有初始标记、并发标记、最终标记、筛选回收,和 CMS 收集器前几步的收集过程很相似:
Java 锁机制
1.什么是锁?
在并发环境下多个线程会对同一个资源进行抢夺,会导致数据不一致问题
synchronized锁有四种状态,无锁,偏向锁,轻量级锁,重量级锁
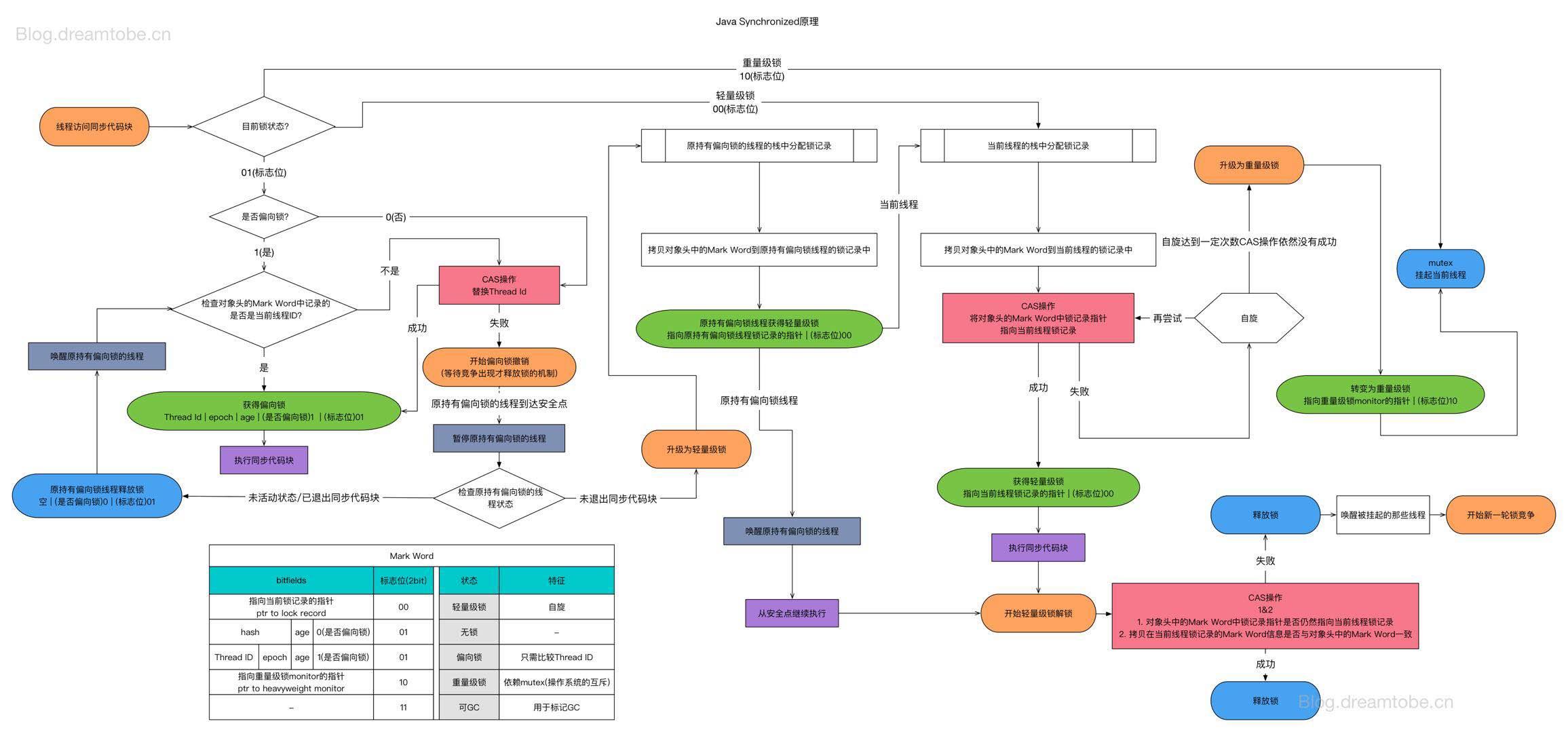
2.CAS 比较和交换


- AQS AbstractQueuesynchronizer 抽象队列同步器
AQS 正是为了解决这个问题而被设计出来的。AQS 是一个集同步状态管理、线程阻塞、线程释放及队列管理功能与一身的同步框架。其核心思想是当多个线程竞争资源时会将未成功竞争到资源的线程构造为 Node 节点放置到一个双向 FIFO 队列中。被放入到该队列中的线程会保持阻塞直至被前驱节点唤醒。值得注意的是该队列中只有队首节点有资格被唤醒竞争锁。
Spring
1.在 Spring 中,构成应用程序主干并由Spring IoC容器管理的对象称为bean。bean是一个由Spring IoC容器实例化、组装和管理的对象
2.BeanPostProcessor作用:对Spring工厂创建的对象进行再加工
3.Bean的生命周期
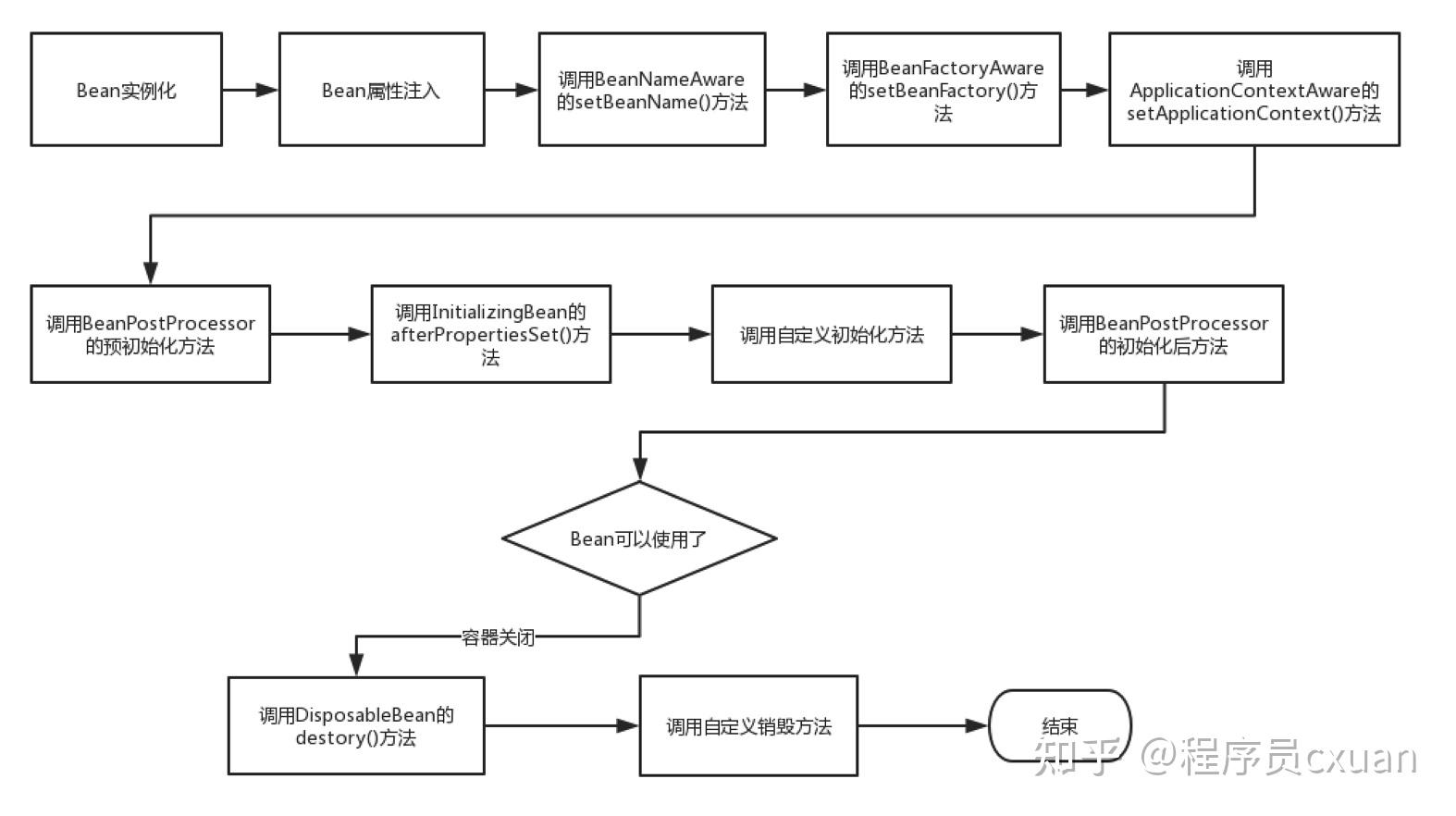
bean 的生命周期
如上图所示,Bean 的生命周期还是比较复杂的,下面来对上图每一个步骤做文字描述:
- Spring启动,查找并加载需要被Spring管理的bean,进行Bean的实例化
- Bean实例化后对将Bean的引入和值注入到Bean的属性中
- 如果Bean实现了BeanNameAware接口的话,Spring将Bean的Id传递给setBeanName()方法
- 如果Bean实现了BeanFactoryAware接口的话,Spring将调用setBeanFactory()方法,将BeanFactory容器实例传入
- 如果Bean实现了ApplicationContextAware接口的话,Spring将调用Bean的setApplicationContext()方法,将bean所在应用上下文引用传入进来
- 如果Bean实现了BeanPostProcessor接口,Spring就将调用他们的postProcessBeforeInitialization()方法。
- 如果Bean 实现了InitializingBean接口,Spring将调用他们的afterPropertiesSet()方法。类似的,如果bean使用init-method声明了初始化方法,该方法也会被调用
- 如果Bean 实现了BeanPostProcessor接口,Spring就将调用他们的postProcessAfterInitialization()方法。
- 此时,Bean已经准备就绪,可以被应用程序使用了。他们将一直驻留在应用上下文中,直到应用上下文被销毁。
- 如果bean实现了DisposableBean接口,Spring将调用它的destory()接口方法,同样,如果bean使用了destory-method 声明销毁方法,该方法也会被调用。
4.@Resources按名字,是JDK的,@Autowired按类型,属于spring
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:p="http://www.springframework.org/schema/p"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-4.0.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd">
<bean name="car1" class="com.hy.spring.pojo.Car">
<property name="name" value="BMW1"></property>
<property name="color" value="red"></property>
</bean>
<bean name="car2" class="com.hy.spring.pojo.Car">
<property name="name" value="BMW2"></property>
<property name="color" value="blue"></property>
</bean>
</beans>
@Resource(name="car1")
private Car mycar;
//@Qualifier注解可以消除需要注入哪个 bean 的问题
@Autowired
@Qualifier("car1")
private Car mycar;
5.Spring 事务详解
(1)什么是事务?
事务是逻辑上的一组操作,要么都执行,要么都不执行.

原子性: 事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用;
一致性: 执行事务前后,数据保持一致;
隔离性: 并发访问数据库时,一个用户的事物不被其他事物所干扰,各并发事务之间数据库是独立的;
持久性: 一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响。
(2)spring 事务管理接口
Spring 框架中,最重要的事务管理的 API 有三个:TransactionDefinition、PlatformTransactionManager 和 TransactionStatus。
- PlatformTransactionManager: (平台)事务管理器
- TransactionDefinition: 事务定义信息(事务隔离级别、传播行为、超时、只读、回滚规则)
- TransactionStatus: 事务运行状态
那么什么是事务属性呢?
事务属性可以理解成事务的一些基本配置,描述了事务策略如何应用到方法上。事务属性包含了5个方面。

脏读(Dirty read): 当一个事务正在访问数据并且对数据进行了修改,而这种修改还没有提交到数据库中,这时另外一个事务也访问了这个数据,然后使用了这个数据。因为这个数据是还没有提交的数据,那么另外一个事务读到的这个数据是“脏数据”,依据“脏数据”所做的操作可能是不正确的。
丢失修改(Lost to modify): 指在一个事务读取一个数据时,另外一个事务也访问了该数据,那么在第一个事务中修改了这个数据后,第二个事务也修改了这个数据。这样第一个事务内的修改结果就被丢失,因此称为丢失修改。
例如:事务1读取某表中的数据A=20,事务2也读取A=20,事务1修改A=A-1,事务2也修改A=A-1,最终结果A=19,事务1的修改被丢失。
不可重复读(Unrepeatableread): 指在一个事务内多次读同一数据。在这个事务还没有结束时,另一个事务也访问该数据。那么,在第一个事务中的两次读数据之间,由于第二个事务的修改导致第一个事务两次读取的数据可能不太一样。这就发生了在一个事务内两次读到的数据是不一样的情况,因此称为不可重复读。
幻读(Phantom read): 幻读与不可重复读类似。它发生在一个事务(T1)读取了几行数据,接着另一个并发事务(T2)插入了一些数据时。在随后的查询中,第一个事务(T1)就会发现多了一些原本不存在的记录,就好像发生了幻觉一样,所以称为幻读。
TransactionDefinition 接口中定义了五个表示隔离级别的常量:
TransactionDefinition.ISOLATION_DEFAULT: 使用后端数据库默认的隔离级别,Mysql 默认采用的 REPEATABLE_READ隔离级别 Oracle 默认采用的 READ_COMMITTED隔离级别.
TransactionDefinition.ISOLATION_READ_UNCOMMITTED: 最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读
TransactionDefinition.ISOLATION_READ_COMMITTED: 允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生
TransactionDefinition.ISOLATION_REPEATABLE_READ: 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。
TransactionDefinition.ISOLATION_SERIALIZABLE: 最高的隔离级别,完全服从ACID的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。但是这将严重影响程序的性能。通常情况下也不会用到该级别。
2)事务传播行为(为了解决业务层方法之间互相调用的事务问题):
当事务方法被另一个事务方法调用时,必须指定事务应该如何传播。例如:方法可能继续在现有事务中运行,也可能开启一个新事务,并在自己的事务中运行。在TransactionDefinition定义中包括了如下几个表示传播行为的常量:
支持当前事务的情况:
TransactionDefinition.PROPAGATION_REQUIRED: 如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务。
TransactionDefinition.PROPAGATION_SUPPORTS: 如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务的方式继续运行。
TransactionDefinition.PROPAGATION_MANDATORY: 如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常。
不支持当前事务的情况:
TransactionDefinition.PROPAGATION_REQUIRES_NEW: 创建一个新的事务,如果当前存在事务,则把当前事务挂起。
TransactionDefinition.PROPAGATION_NOT_SUPPORTED: 以非事务方式运行,如果当前存在事务,则把当前事务挂起。
TransactionDefinition.PROPAGATION_NEVER: 以非事务方式运行,如果当前存在事务,则抛出异常。
其他情况:
TransactionDefinition.PROPAGATION_NESTED: 如果当前存在事务,则创建一个事务作为当前事务的嵌套事务来运行;如果当前没有事务,则该取值等价于TransactionDefinition.PROPAGATION_REQUIRED。
这里需要指出的是,前面的六种事务传播行为是 Spring 从 EJB 中引入的,他们共享相同的概念。而 PROPAGATION_NESTED 是 Spring 所特有的。以 PROPAGATION_NESTED 启动的事务内嵌于外部事务中(如果存在外部事务的话),此时,内嵌事务并不是一个独立的事务,它依赖于外部事务的存在,只有通过外部的事务提交,才能引起内部事务的提交,嵌套的子事务不能单独提交。如果熟悉 JDBC 中的保存点(SavePoint)的概念,那嵌套事务就很容易理解了,其实嵌套的子事务就是保存点的一个应用,一个事务中可以包括多个保存点,每一个嵌套子事务。另外,外部事务的回滚也会导致嵌套子事务的回滚。
| 传播属性的值 | 外部不存在事务 | 外部存在事务 | 备注 | 用法 |
|---|---|---|---|---|
| REQUIRED | 开启新的事务 | 融合到外部事务中 | 增删改方法 | @Transactional(propagation=Propagation.REQUIRED) |
| SURRPORTS | 不开启事务 | 融合到外部事务中 | 查询方法 | @Transactional(propagation=Propagation.SURRPORTS) |
| REQUIRED_NEW | 开启新的事务 | 挂起外部事务,创建新的事务 | 日志记录方法 | @Transactional(propagation=Propagation.REQUIRED_NEW) |
| NOT_SURRPORTED | 不开启事务 | 挂起外部事务 | 不常用 | @Transactional(propagation=Propagation.NOT_SURRPORTED) |
| NEVER | 不开启事务 | 抛出异常 | 不常用 | @Transactional(propagation=Propagation.NEVER) |
| MANDATORY | 抛出异常 | 融合到外部事务中 | 不常用 | @Transactional(propagation=Propagation.MANDATORY) |
6.Spring MVC流程
1、 用户发送请求至前端控制器DispatcherServlet。
2、 DispatcherServlet收到请求调用HandlerMapping处理器映射器。
3、 处理器映射器找到具体的处理器(可以根据xml配置、注解进行查找),生成处理器对象及处理器拦截
器(如果有则生成)一并返回给DispatcherServlet。
4、 DispatcherServlet调用HandlerAdapter处理器适配器。
5、 HandlerAdapter经过适配调用具体的处理器(Controller,也叫后端控制器)。
6、 Controller执行完成返回ModelAndView。
7、 HandlerAdapter将controller执行结果ModelAndView返回给DispatcherServlet。
8、 DispatcherServlet将ModelAndView传给ViewReslover视图解析器。
9、 ViewReslover解析后返回具体View。
10、DispatcherServlet根据View进行渲染视图(即将模型数据填充至视图中)。
11、 DispatcherServlet响应用户
Spring Boot
1.Spring Boot提供了两种 “开机自启动” 的方式,ApplicationRunner和Spring Boot提供了两种 “开机自启动” 的方式,ApplicationRunner和CommandLineRunner