
问题记录
[toc]
一、自我介绍
我是谁
各位面试官下午好,我是,今年xx岁,自2021年毕业后在xx任职后端开发,工作期间主要负责dbaas云平台的相关模块的开发,dbaas云平台主要为db团队提供服务,可以方便快捷的创建 管理 释放数据库资源,以及提供对数据库集群的监控和数据采集服务,我主要负责相关接口的开发,添加对不同集群监控功能 修改审批wprkflow流程 api接口供其他team调用 根据需求拓展相应功能
为什么我胜任
我在xx工作期间,项目经历主要分为两部分,
第一部分是参与DBaaS平台的开发,dbaas云平台主要为db团队提供服务,可以方便快捷的创建 管理 释放数据库资源,以及提供对数据库集群的监控和数据采集服务,工作期间主要负责dbaas云平台的相关模块的开发,我主要负责相关接口的开发,添加对不同集群监控功能 修改审批wprkflow流程 api接口供其他team调用 根据需求拓展相应功能
第二部分是dashboard自动化,对aws创建的集群自动创建仪表盘,对集群相关指标数据的展示,包括cpu 内存 客户端请求数
为什么我来面试
我的求职意向是软件开发工程师。2年项目开发经验,熟悉Java编程语言,参与多个项目开发,了解项目完整部署流程,期待加入新的团队进一步成长!
今年xx岁,自2021年毕业后在xx任职后端开发,工作期间主要负责dbaas云平台的相关模块的开发,dbaas云平台主要为db团队提供服务,可以方便快捷的创建 管理 释放数据库资源,以及提供对数据库集群的监控和数据采集服务,我主要负责相关接口的开发,添加对不同集群监控功能 修改审批wprkflow流程 api接口供其他team调用 根据需求拓展相应功能
另一个项目就是dashboard自动化,对aws创建的集群自动创建仪表盘,对集群相关指标数据的展示,包括cpu 内存 客户端请求数
审批流程
workflow rbac task处理 信息发送 call api 信息配置 异步任务处理
哪些最为擅长?接口开发???
Postgresql索引
你好,我对贵公司发布的岗位很感兴趣,有2年后端开发经验,希望能与你沟通一下
二、社招问题
(1)大智慧财汇:
1. springboot自动装配在哪一步哪一个流程
2. 线程间通信方式
共享内存:线程之间共享程序的公共状态,线程之间通过读-写内存中的公共状态来隐式通信。
volatile共享内存
消息传递:线程之间没有公共的状态,线程之间必须通过明确的发送信息来显示的进行通信。
wait/notify等待通知方式 join方式
管道流
管道输入/输出流的形式
3. 线程发生死锁的情况下如何解决
以下是一些常见的解决方法:
避免循环等待:
设计代码时,尽量避免出现循环等待的情况。尽量按照相同的顺序获取锁,以减少死锁的可能性。
使用tryLock()方法:
Java中的ReentrantLock类提供了tryLock()方法,可以尝试获取锁,如果获取失败,则可以放弃等待,执行其他操作,或者等待一段时间后再尝试。
使用lockInterruptibly()方法:
ReentrantLock类的lockInterruptibly()方法允许线程在等待锁的过程中响应中断,从而可以通过中断来打破死锁。
设置获取锁的超时时间:
使用tryLock(long time, TimeUnit unit)方法,允许线程在一定时间内尝试获取锁,如果获取不到,则可以放弃等待或进行其他操作。
使用Executor框架:
使用Java的Executor框架可以更好地管理线程,从而降低死锁的风险。线程池管理线程分配和调度,减少手动管理锁的需求。
资源有序性:
设计时,尽量对资源进行排序,以确保线程按照相同的顺序获取锁,从而降低死锁的可能性。
定期检测和恢复:
可以通过定时检测线程状态,发现死锁后进行恢复操作。这可能包括终止某些线程,释放资源等。
使用事务:
在某些情况下,使用分布式事务来处理资源的获取和释放,以避免出现资源未释放而导致死锁的情况。
4. redis和数据库如何保持缓存一致性
缓存延时双删
为什么要延迟双删,来保证缓存一致性
在修改数据库数据前,需要先删除一次redis:此时是为了保证在数据库数据修改和redis数据被删除的间隔时间内,如有命中,保证此数据也不存在redis中。如果没有这一次删除,当数据库数据已经被修改了,但是还是可以从redis中读出旧数据,导致数据不一致。
第二次删除则是在修改数据库数据后,此时需要再次删除redis中对应数据一次,这一次是为了删除 redis删除和数据库数据修改之间,如果有请求,那么旧数据又会重新缓存到redis中,然而数据在数据库中在接下来就会被修改,如果没有这一次删除,redis中则会存在数据库中旧的数据。
那么第二次为什么需要在数据库修改后延迟一定时间再删除redis呢?
为了等待之前的一次读取数据库,并等待其数据写入到缓存,最后删除这次脏数据,所以是一次数据从数据库中发到服务器+缓存写入的时间
5. 线程池有哪些类型?
https://juejin.cn/post/6890701585169678344
ThreadPoolTaskExecutor:spring自带的, 对ThreadPoolExecutor的简单封装
(1) corePoolSize:核心线程数。
(2) maximumPoolSize:最大线程数。
(3) keepAliveTime:空闲线程存活时间。
(4) TimeUnit:时间单位。
(5) BlockingQueue:线程池任务队列。
它可以设置以下几个值:
ArrayBlockingQueue:一个由数组结构组成的有界阻塞队列。
LinkedBlockingQueue:一个由链表结构组成的有界阻塞队列。
SynchronousQueue:一个不存储元素的阻塞队列,即直接提交给线程不保持它们。
PriorityBlockingQueue:一个支持优先级排序的无界阻塞队列。
DelayQueue:一个使用优先级队列实现的无界阻塞队列,只有在延迟期满时才能从中提取元素。
LinkedTransferQueue:由链表结构组成的无界阻塞队列。与SynchronousQueue类似,还含有非阻塞方法。
LinkedBlockingDeque:一个由链表结构组成的双向阻塞队列。
(6) ThreadFactory:创建线程的工厂。
(7) RejectedExecutionHandler:拒绝策略。
FixedThreadPool(固定线程池):
这是一种固定大小的线程池,线程数量固定不变。适用于并发请求比较稳定的场景。
ExecutorService executorService = Executors.newFixedThreadPool(3);
CachedThreadPool(缓存线程池):
这是一种根据需要自动调整线程数量的线程池。适用于并发请求数量较大但不确定的场景。
SingleThreadExecutor(单线程池):
只包含一个线程的线程池,适用于需要顺序执行任务的场景。
ScheduledThreadPool(定时任务线程池):
用于执行定时任务和周期性任务的线程池,可以预定执行任务。
6. jvm和垃圾收集器
7. mybatis底层原理
SqlSessionFactory
SqlSession
mapper
8. redis最大扩展数量?为什么?
2^14^=16384、2^16^=65536。
如果槽位是65536个,发送心跳信息的消息头是65536/8/1024 = 8k。
如果槽位是16384个,发送心跳信息的消息头是16384/8/1024 = 2k。
因为Redis每秒都会发送一定数量的心跳包,如果消息头是8k,未免有些太大了,浪费网络资源。
上面提过,Redis的集群主节点数量一般不会超过1000个。集群中节点越多,心跳包的消息体内的数据就越多,如果节点过多,也会造成网络拥堵。因此Redis的作者Salvatore Sanfilippo不建议Redis Cluster的节点超过1000个,对于节点数在1000个以内的Redis Cluster,16384个槽位完全够用。
9. docker查看容器环境变量
(1) docker inspect container
(2) docker exec container env
10. 深度优先搜索(Depth-First Search)和广度优先搜索(Breadth-First Search)
深度优先搜索 (DFS):
思想: DFS 采用深度优先的策略,从起始节点开始,沿着一条路径一直走到底,直到无法再继续前进,然后回退到上一个节点,继续探索下一个路径,如此类推,直到遍历完整个图或找到目标节点。
递归和栈: DFS 可以使用递归或栈来实现。递归的方式更自然,而栈通常用于非递归实现。
广度优先搜索 (BFS):
思想: BFS 采用广度优先的策略,从起始节点开始,首先探索起始节点的所有相邻节点,然后再依次探索相邻节点的相邻节点,以此类推,直到找到目标节点或遍历完整个图。
队列: BFS 使用队列来实现,保证了先进先出(FIFO)的顺序,确保了节点的层级遍历。
11. 数据库 SQL 优化是提高数据库性能的关键部分之一。下面是一些常见的数据库 SQL 优化方案,包括添加索引、查询优化、表设计等:
(1)添加索引(Indexing):
添加适当的索引可以显著提高查询性能。在经常用于筛选、排序或连接的列上创建索引。
谨慎使用复合索引,以确保索引的组合对查询有用。
定期重新构建或重新组织索引,以保持索引的性能。
(2)查询优化:
编写高效的 SQL 查询,避免不必要的子查询、联接和过滤条件。
使用数据库查询计划(Query Execution Plan)工具来分析查询的执行计划,并优化查询。
尽量减少 SELECT * 查询,只选择需要的列。
使用 LIMIT 和 OFFSET 进行分页查询。
表设计(Table Design):
(3)使用合适的数据类型来存储数据,避免过度使用大文本字段。
规范化和反规范化表结构,根据应用程序的需求来决定表的设计。
避免表中的大型 BLOB 或 CLOB 数据。
硬件升级:
(4)升级数据库服务器的硬件,包括 CPU、内存和存储设备,以提高数据库性能。
考虑使用固态硬盘(SSD)来加速数据读写操作。
连接池(Connection Pooling):
(5)使用连接池来管理数据库连接,以避免频繁的连接和断开连接操作。
配置连接池的最大连接数,以防止资源过度消耗。
缓存数据(Caching):
(6)使用缓存来存储经常访问的数据,减少对数据库的访问。
使用分布式缓存系统,如Redis,来提高数据的读取性能。
分区表(Partitioning):
(7)对大型表进行分区,将数据划分到多个物理表中,以减少查询的数据量。
根据时间范围或其他条件进行分区。
定期维护(Maintenance):
(8)定期进行数据库备份和日志清理。
清理无用的索引和数据。
更新数据库统计信息,以帮助查询优化器生成更好的查询计划。
异步处理(Asynchronous Processing):
(9)将一些查询或数据处理任务异步化,以减轻主数据库的负载。
使用消息队列来处理后台任务。
数据库升级:
(10)更新数据库管理系统(DBMS)到最新版本,以获得性能和安全性的改进。
监控和性能分析:
(11)使用数据库性能监控工具来实时监测数据库性能,及时识别和解决问题。
12. ReentrantLock的基本实现可以概括为:先通过CAS尝试获取锁。如果此时已经有线程占据了锁,那就加入AQS队列并且被挂起。当锁被释放之后,排在CLH队列队首的线程会被唤醒,然后CAS再次尝试获取锁。在这个时候,如果:
非公平锁:如果同时还有另一个线程进来尝试获取,那么有可能会让这个线程抢先获取;
公平锁:如果同时还有另一个线程进来尝试获取,当它发现自己不是在队首的话,就会排到队尾,由队首的线程获取到锁。
java8 默认GC parallel
在 Java 9 及以后的版本中,默认的垃圾回收器是 G1 垃圾回收器(G1 Garbage Collector)。
1. spring如何解决bean的循环依赖问题?
Spring 使用三级缓存解决循环依赖问题。循环依赖是指多个 Bean 之间相互依赖,形成一个循环链,例如 A 依赖 B,B 依赖 C,C 又依赖 A。这种情况下,Spring 需要确保正确地创建和初始化这些 Bean,以避免死锁和无限递归。
三级缓存是 Spring 在创建 Bean 的过程中用于解决循环依赖的一种机制,分为三个阶段:singletonObjects、earlySingletonObjects 和 singletonFactories。
singletonObjects: 这是一级缓存,用于存放完全初始化好的 Bean 实例。
earlySingletonObjects: 这是二级缓存,用于存放已经创建但未完全初始化的 Bean 实例。这些实例已经通过构造函数创建,但尚未进行依赖注入和初始化。
singletonFactories: 这是三级缓存,用于存放 Bean 的工厂方法。当创建 Bean 时,Spring 会首先从三级缓存中查找,如果找到工厂方法,则使用工厂方法创建 Bean 实例。
解决循环依赖的过程大致如下:
Spring 首先在一级缓存中查找 Bean,如果找到,则直接返回。
如果一级缓存中没有,Spring 会尝试从二级缓存中查找。如果找到,会将 Bean 完成依赖注入和初始化,然后放入一级缓存,并从二级缓存中移除。
如果二级缓存中没有,Spring 会尝试从三级缓存中查找 Bean 的工厂方法。如果找到工厂方法,则使用工厂方法创建 Bean 实例,并放入一级缓存。
创建完成后,Spring 将 Bean 放入二级缓存,并从三级缓存中移除。
需要注意的是,Spring 的默认循环依赖解决策略是使用三级缓存。然而,如果循环依赖关系过于复杂,或者构造函数中存在循环依赖,可能会导致解决循环依赖失败。在这种情况下,最好重新考虑设计,尽量避免循环依赖。
如果你使用 Spring Boot,一般情况下不需要显式地处理循环依赖问题,因为 Spring Boot 提供了默认的 Bean 实例化顺序和循环依赖处理机制。
2. 引入泛型的目的
泛型(Generics)是 Java 编程语言的一个重要特性,引入了泛型的目的是为了提高代码的类型安全性和可重用性。泛型允许你在编写代码时使用参数化类型(也称为类型参数),以便在编译时检查和强制类型安全。泛型的主要目的是减少代码重复,提高代码的灵活性,同时提供更好的类型检查。
3. HTTP状态码
信息响应 (100–199)
成功响应 (200–299)
重定向消息 (300–399)
客户端错误响应 (400–499)
服务端错误响应 (500–599)
https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Status
4. 项目中对分页的实现 (mybatis mybatis-plus)
https://www.cnblogs.com/tanghaorong/p/14017180.html
mybatis: limit offset语句, rowbound, 自定义拦截器, pageHelper
mybatis-plus:
@Service
public class YourEntityService extends ServiceImpl<YourEntityMapper, YourEntity> {
public IPage<YourEntity> findEntitiesByPage(int pageNum, int pageSize) {
Page<YourEntity> page = new Page<>(pageNum, pageSize);
return baseMapper.selectPage(page, null);
}
}
Wrapper 条件构造器查询
5. IO模型
多路复用是一种 I/O 处理模型,它允许单个线程同时监视多个文件描述符(套接字、文件句柄等),以检测是否有数据可供读取或写入。多路复用的目标是提高系统的性能和资源利用率,减少不必要的阻塞。
在 Java 中,常用的多路复用技术包括 select、poll 和 epoll。它们在实现细节和性能方面有一些区别:
select:
select 是最早引入的多路复用技术之一,存在于 Unix 系统中。
通过一个 fd_set 结构体来表示文件描述符集合,然后通过系统调用 select 来监听这些文件描述符的事件。
select 最大的问题是,它有一个固定大小的文件描述符集合,因此在处理大量文件描述符时可能会有性能问题。
不支持事件触发方式,每次都需要轮询检查所有文件描述符,这会导致性能低下。
poll:
poll 是对 select 的改进,它也是 Unix 系统的一部分。
poll 使用一个动态分配的数据结构来存储文件描述符集合,因此不受文件描述符数量的限制。
与 select 类似,poll 也需要轮询检查文件描述符的状态。
epoll:
epoll 是 Linux 特有的多路复用技术,引入了事件驱动模型,性能更高。
epoll 使用一个事件数组来存储文件描述符和相应的事件,只有在发生事件时才会通知程序。
epoll 支持水平触发和边缘触发两种触发方式,可以根据需要选择。
由于 epoll 使用了事件驱动模型,它对大量文件描述符的处理性能非常出色。
6. 区别:BeanFactory是个Factory,也就是IOC容器或对象工厂,FactoryBean是个Bean。在Spring中,所有的Bean都是由BeanFactory(也就是IOC容器)来进行管理的。但对FactoryBean而言,这个Bean不是简单的Bean,而是一个能生产或者修饰对象生成的工厂Bean,它的实现与设计模式中的工厂模式和修饰器模式类似
7. Spring Boot的@Transactional注解是基于Spring框架中的@Transactional注解的扩展,用于声明事务性方法。@Transactional注解的底层原理涉及Spring框架的事务管理机制,主要是Spring的AOP(面向切面编程)和事务管理器。
service层写接口再写impl,即是为了实现aop代理,事务
8. mybatis联表查询 子查询
9. springboot启动流程
创建 SpringApplication ->分析环境、推断类型(Web/非Web)
配置监听器 -> 注册 SpringApplicationRunListener
构建 Environment -> 读取配置文件、系统变量、命令行参数
创建 IOC 容器 -> 选择合适的 ApplicationContext
自动装配 -> 加载自动配置类、注入所需的 Bean
执行 Runner -> ApplicationRunner、CommandLineRunner
完成启动 -> 发布 ApplicationReadyEvent
10. spring bean的生命周期
(1) 实例化(Instantiation)
(2) 属性赋值(Populate Properties)
(3) Aware 接口回调(xxxAware)
(4) 初始化前处理(BeanPostProcessor.beforeInit)
(5) 初始化(InitializingBean.afterPropertiesSet 或 init-method)
(6) 初始化后处理(BeanPostProcessor.afterInit)
(7) Bean 就绪(可使用状态)
(8) 销毁前处理(DisposableBean 或 destroy-method)
(9) Bean 被销毁(容器关闭或手动销毁)
事务传播
https://blog.csdn.net/qq_35493807/article/details/105756761
SpringBoot具有 七 种事务传播机制:
| propagation值 | 说明 |
|---|---|
| REQUIRED | 如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务。 |
| SUPPORTS | 如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务的方式继续运行。 |
| MANDATORY | 如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常。 |
| REQUIRES_NEW | 创建一个新的事务,如果当前存在事务,则把当前事务挂起。 这个方法会独立提交事务,不受调用者的事务影响,父级异常,它也是正常提交 |
| NOT_SUPPORTED | 以非事务方式运行,如果当前存在事务,则把当前事务挂起。 |
| NEVER | 以非事务方式运行,如果当前存在事务,则抛出异常。 |
| NESTED | 如果当前存在事务,它将会成为父级事务的一个子事务,方法结束后并没有提交,只有等父事务结束才提交 如果当前没有事务,则新建事务 如果它异常,父级可以捕获它的异常而不进行回滚,正常提交 但如果父级异常,它必然回滚,这就是和 REQUIRES_NEW 的区别 |
@Transactional(propagation = Propagation.REQUIRED)
1:REQUIRED
spring的默认传播行为。
作用:
** 支持事务,如果业务方法执行时在一个事务中,则加入当前事务,否则则重新开始一个事务。
外层事务提交了,内层才会提交。
内/外只要有报错,他俩会一起回滚。(栗子二,三)
只要内层方法报错抛出异常,即使外层有try-catch,该事务也会回滚!(栗子一)
内层不存在事务,外层存在事务,即加入外层的事务,不管内层,外层报错,都会回滚事务。**
栗子一:
条件:外层正常try-catch内层,内层出错。
结果:事务回滚,内层外层都回滚。
栗子二:
条件:外层正常,内层出错,外层不try-catch
结果:事务回滚,内层外层都回滚。
栗子三:
条件:外层出错,内层正常
结果:事务回滚,内层外层都回滚。
2:REQUIRES_NEW
作用:
** 支持事务。每次都是创建一个新事物,如果当前已经在事务中了,会挂起当前事务。
内层事务结束,内层就提交了,不用等着外层一起提交。
外层报错回滚,不影响内层。(栗子一)
内层报错回滚,外层try-catch内层的异常,外层不会回滚。(栗子二)
内层报错回滚,然后又会抛出异常,外层如果没有捕获处理内层抛出来的这个异常,外层还是会回滚的。(栗子三)**
栗子一:
内层正常,外层报错。
结果:内层提交,外层回滚。
栗子二:
内层报错,外层try-catch。
结果:外层提交,内层回滚。
栗子三:
内层报错,外层不try-catch。
结果:外层回滚,内层回滚。
3:NESTED
作用:
** 支持事务。如果当前已经在一个事务中了,则嵌套在已有的事务中作为一个子事务。如果当前没在事务中则开启一个事务。
内层事务结束,要等着外层一起提交。
外层回滚,内层也回滚。(栗子一)
如果只是内层回滚,影响外层。(栗子二)[因为默认成为了子事务]
如果只是内层回滚,外层try-catch内层的异常,不影响外层。(栗子三)
这个内层回滚不影响外层的特性是有前提的,否则内外都回滚。**
前提:
**1.JDK版本要在1.4以上,有java.sql.Savepoint。因为nested就是用savepoint来实现的。
2.事务管理器的nestedTransactionAllowed属性为true。
3.外层try-catch内层的异常。
**
栗子一:
内层正常,外层报错。
结果:内层回滚,外层回滚。
栗子二:
内层报错,外层正常。
结果:内层回滚,外层回滚。
栗子三:
内层报错,外层正常try /catch 内层。
结果:内层回滚,外层提交。
4:SUPPORTS
作用:
** 支持事务。当前有事务就加入当前事务。当前没有事务就算了,不会开启一个事物。**
栗子一:
外层正常有事务,内层报错。
结果:外层回滚,内层回滚。
栗子二:
外层正常有事务try/catch,内层报错。
结果:外层回滚,内层回滚。
栗子三:
外层报错有事务,内层正常。
结果:外层回滚,内层回滚。
栗子四:
外层正常无事务,内层报错。
结果:外层提交,内层提交。
5:MANDATORY
作用:
** 支持事务,如果业务方法执行时已经在一个事务中,则加入当前事务。否则抛出异常。**
栗子一:
外层正常有事务,内层报错。
结果:外层回滚,内层回滚。
栗子二:
外层正常无事务,内层报错。
结果:外层提交,内层回滚。
6:NOT_SUPPORTED
作用:
** 不支持事务,如果业务方法执行时已经在一个事务中,则挂起当前事务,等方法执行完毕后,事务恢复进行。**
栗子一:
外层正常有事务,内层报错。
结果:外层回滚,内层提交。
栗子二:
外层正常有事务try/catch内层,内层报错。
结果:外层提交,内层提交。
7:NEVER
作用:
** 不支持事务。如果当前已经在一个事务中了,抛出异常。数据回滚。**
栗子一:
外层正常有事务,内层报错。
结果:外层回滚,内层回滚。
栗子二:
外层正常无事务,内层报错。
结果:外层提交,内层提交。
栗子三:
外层报错有事务,内层正常。
结果:外层回滚,内层回滚。
Future<Integer> future同步阻塞等待结果
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Future;
public class FutureExample {
public static void main(String[] args) {
// 创建一个线程池
ExecutorService executorService = Executors.newFixedThreadPool(1);
// 提交一个带有返回值的任务给线程池
Future<Integer> future = executorService.submit(() -> {
Thread.sleep(2000); // 模拟耗时操作
return 42;
});
// 在后续的代码中获取计算的结果
try {
// 阻塞等待任务完成,并获取结果
Integer result = future.get();
System.out.println("计算结果: " + result);
} catch (Exception e) {
e.printStackTrace();
}
// 关闭线程池
executorService.shutdown();
}
}
CompletableFuture异步等待结果
import java.util.concurrent.CompletableFuture;
import java.util.concurrent.ExecutionException;
public class CompletableFutureExample {
public static void main(String[] args) {
// 异步执行任务
CompletableFuture<Integer> future = CompletableFuture.supplyAsync(() -> {
try {
Thread.sleep(2000); // 模拟耗时操作
} catch (InterruptedException e) {
e.printStackTrace();
}
return 42;
});
// 在其他线程中异步等待任务的结果
future.thenAcceptAsync(result -> {
System.out.println("计算结果: " + result);
});
// 主线程可以继续执行其他任务
System.out.println("主线程继续执行其他任务");
// 等待异步任务完成(如果需要)
try {
future.get(); // 可以等待异步任务完成,也可以不等待
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
}
}
TLS就是通过这种方式进行加密的。两者结合后,使用非对称加密的方式应该尽量降低,才能保证传输的效率。因此,TLS的规则就是:服务端生成非对称秘钥对,私钥自己保存,将公钥明文传输给客户端;客户端生成一个对称秘钥,再将对称秘钥使用收到的公钥进行加密,将加密后的秘钥传送给服务端;这样双端都持有相同的对称秘钥,之后的数据就通过该秘钥进行加密再传输。
redis
(1) 主从模式
从节点加入到主节点命令
slaveof ip port
or
replicaof 127.0.0.1 6001
取消
通过输入replicaof no one,即可变回Master角色
全局异常处理
Springboot对于异常的处理也做了不错的支持,
它提供了一个 @ControllerAdvice注解以及 @ExceptionHandler注解,前者是用来开启全局的异常捕获,后者则是说明捕获哪些异常,对那些异常进行处理。
@ControllerAdvice
public class MyExceptionHandler {
@ExceptionHandler(value =Exception.class)
public String exceptionHandler(Exception e){
System.out.println("发生了一个异常"+e);
return e.getMessage();
}
}
原子性 可见性 有序性
I have received the compensation, can you provide me with the details?
In addition, does this compensation include holiday commutation?
oauth2
如果oauth2仅仅验证用户登录,授权是根据用户名称从数据库查询权限呢?怎么写代码
用户登录->跳转统一验证平台oauth2校验->返回token等信息->程序根据username从数据库加载对应权限
oauth2返回的数据格式:
access_token: 访问令牌,用于访问受保护的资源。
token_type: 令牌类型,通常是 "Bearer"。
expires_in: 令牌的有效期,以秒为单位。
refresh_token: 刷新令牌,用于获取新的访问令牌。
scope: 令牌的权限范围。
其他自定义字段,如用户信息、角色、用户ID等。
在使用Spring Security和OAuth2的情况下,loadUserByUsername(String username) 方法的参数username通常是由OAuth2流程传递的,而不是手动传递的。当OAuth2授权成功后,Spring Security会自动获取OAuth2令牌中的用户信息,并将其传递给loadUserByUsername方法。
@Service
public class CustomUserDetailsService implements UserDetailsService {
@Override
public UserDetails loadUserByUsername(String username) throws UsernameNotFoundException {
// 在这里,Spring Security会自动传递OAuth2令牌中的用户名
// 您可以使用这个用户名从数据库或其他数据源加载用户信息
// 示例中,假设从数据库中加载用户信息
User user = userRepository.findByUsername(username);
if (user == null) {
throw new UsernameNotFoundException("User not found with username: " + username);
}
// 返回UserDetails对象,包括用户名、密码、角色等信息
return new org.springframework.security.core.userdetails.User(
user.getUsername(),
user.getPassword(),
// 在这里可以设置用户的权限
AuthorityUtils.createAuthorityList("ROLE_USER")
);
}
}
@Controller
public class MyController {
@GetMapping("/profile")
public String userProfile() {
Authentication authentication = SecurityContextHolder.getContext().getAuthentication();
if (authentication.getPrincipal() instanceof UserDetails) {
UserDetails userDetails = (UserDetails) authentication.getPrincipal();
// 可以访问 userDetails 中的属性和权限信息
String username = userDetails.getUsername();
// ...
}
return "profile";
}
}
/**
**/
@Configuration
@EnableWebSecurity
public class SecurityConfig extends WebSecurityConfigurerAdapter {
@Autowired
private CustomUserDetailsService customUserDetailsService;
@Override
protected void configure(HttpSecurity http) throws Exception {
// 配置权限控制规则
http
.authorizeRequests()
.antMatchers("/admin/**").hasRole("ADMIN")
.antMatchers("/user/**").hasRole("USER")
.anyRequest().authenticated()
.and()
.formLogin()
.loginPage("/login")
.permitAll()
.and()
.logout()
.permitAll();
}
@Autowired
public void configureGlobal(AuthenticationManagerBuilder auth) throws Exception {
// 使用自定义的 UserDetailsService 来验证用户
auth.userDetailsService(customUserDetailsService);
}
}
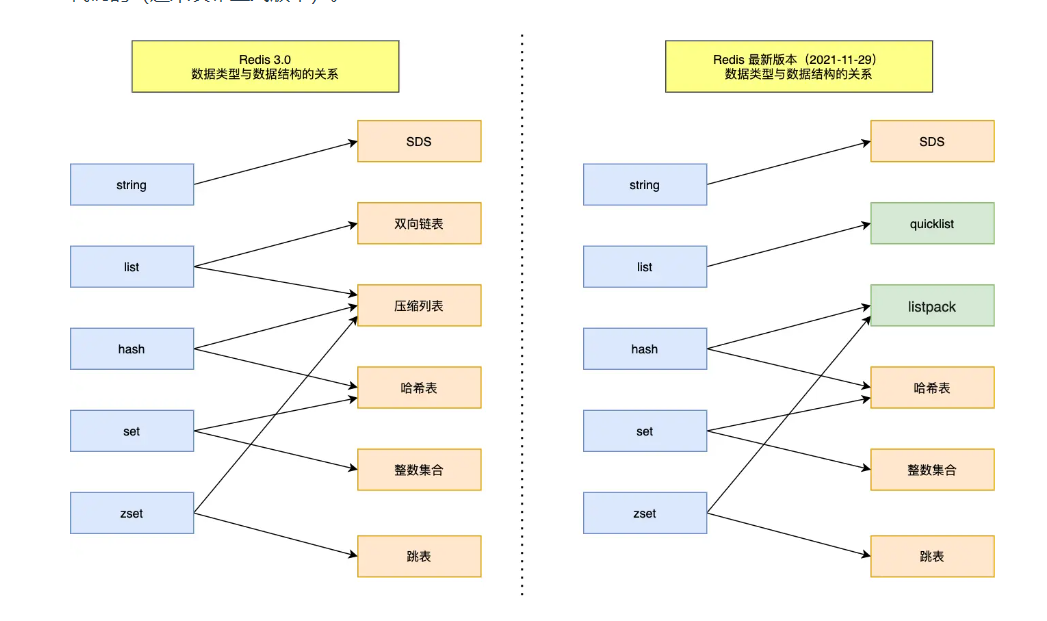
redis 底层数据结构
本文链接:
/archives/wen-ti-ji-lu
版权声明:
本站所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自
晓!
喜欢就支持一下吧